
Packing and Unpacking study notes Pt-1
Hello, here is my study notes for the packing topic, hope anyone finds it useful.
I’ll put all resources that I took information from it in the references section, so, you can take a look at them also.
Why do we care about packing?
Today, most of the malware is packed, and it’s a good skill for a malware analyst to recognize if the PE file is packed or not and also be able to unpack it to get the full sight.
What is the purpose of packing?
Originally, the packer used to shrink the size of executables in the disk like a compressor and if you facing the packed malware you will probably hear something about UPX packer, and this program is a type of compressor.
Also, there are packers used to encrypt the executable, this type is used to evade AV detection and also evade reverse engineering because basic static analysis isn’t useful with packed files, first, you must unpack it and then analyze it.
Packers Anatomy
All Packers programs take an executable file and produce an executable file also, but, the produced contains nothing to inform you anything about the original file functionality, it’s a stub that will decompress or decrypt the original and the compressed or encrypted original file.
Packers also can pack the entire EXE file or only code and data sections
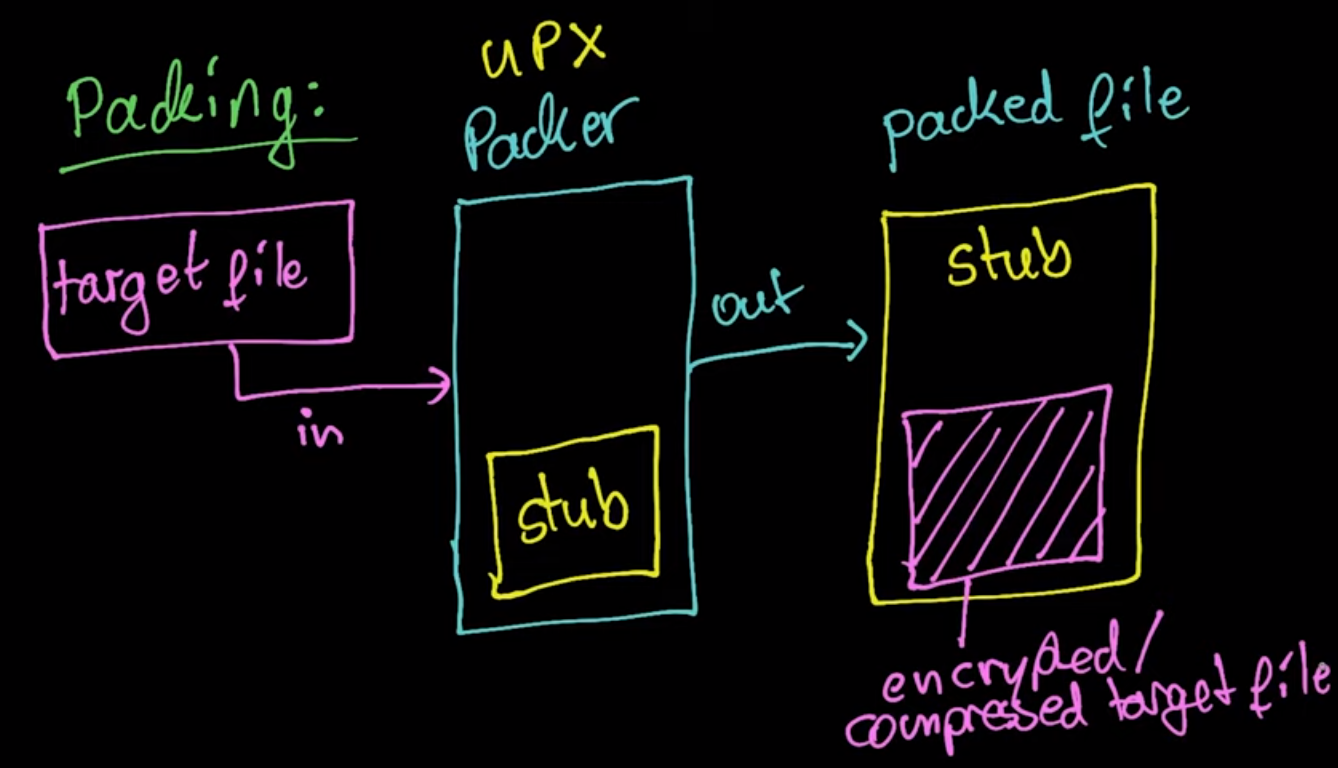
As shown in this image, the packer takes the target file as input and using the stub it will produce the packed file which is stub contains the compressed file.
A stub is a small portion of code that contains the decryption or decompression agent used to decrypt the packed file.
Also, the important thing about the packing process is that the packer relocated/obfuscated the original entry point in the packed section, this process makes identifying the import address table (IAT) and original entry point difficult.
So, the packed file consists of :
- New PE header
- Packed section(s) (that hold out original code)
- Unpacking stub — used to unpack the code
And, the unpacking stub performs three steps:
- Unpacks the original executable into memory
- Resolves all of the imports of the original executable
- Transfers execution to the original entry point (OEP)
How packed file execute the target file?
As we called it Decompression/Unpacking stub, so, the stub will decompress the target file and then there are two ways to execute the original code:
-
Execute the code in the same process space by allocating enough memory space to load the executable into it, and this is the approach used by most legal products like
UPX -
Create a child process and inject the PE file in it using
Process injectiontechniques to run it.
How does the stub know where the compressed/encrypted content is located?
-
Many approaches can be applied in this situation, one of them is that we can add start and end marks at the packed content, so, the stub can find it.
-
Or the easiest approach from my perspective is that we can place the packed content in known places in the PE file like the end of the file or the last section of the file to allow expansion safely without affecting the other sections.
-
The
PE resourcessection is a very common section I see that it holds PE files inside it so we can place the packed content on it. -
A huge
Base64string that contains the encrypted data can also be used, and I faced a similar thing in the Putty Sample
Packing / Unpacking Process Illustrated:
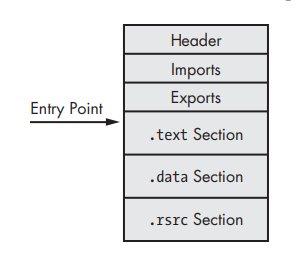
In this image, we can see the anatomy of the regular PE executable, it has imports and maybe export and a regular section, also the Entry point in its regular location points to the start of .text section.
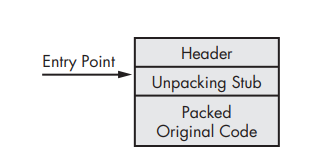
Here, the packed executable looked like in the disk, all we can see in this case is just the header, the unpacking stub, and the packed original code.
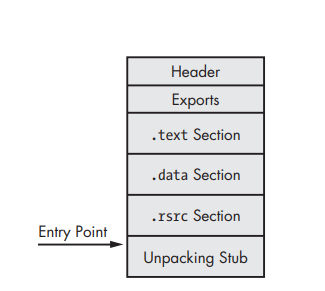
Here, the unpacked executable looks like in the memory, the unpacking stub has unpacked the original executable section, but it doesn’t resolve the imports and the starting point still points to the entry point at the unpacking stub.
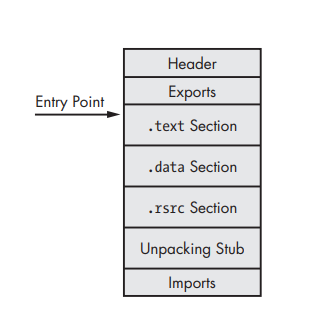
Here, we have a fully unpacked file, the unpacking stub reconstructing the import table and the starting point points to the original OEP.
Note: in this technique, the original executable is unpacked within the unpacked file, so, the final file will be different from the original executable
how the unpacking stub resolves the import of the original executable?
Many approaches can be used by unpacking stub to resolve the original executable.
-
The common one is that the unpacking stub used
LoadLibraryandGetProcAddress, after unpacking the original executable the unpacking stub will read the import information and then usesLoadLibraryto load the DLLs into memory and then useGetProcAddressit can get all imports addresses. -
Another approach is to keep the import table intact, and then after the unpacking stub has unpacked the original executable the Windows loader will use the import table to load all imports that are required by executable. This approach is easy, but also any analyst will know all imports imported by the original executable.
-
In the third approach, the packer will keep only one import from each library and then the unpacking stub doesn’t need to get the library first and then get the functions, instead, it will only get the functions using
GetProcAddress. Also in this approach, the analyst can know all used libraries by this executable. -
The complicated approach, the packer won’t keep any imports, including
LoadLibraryandGetProcAddress, the unpacking stub must find all the functions needed from other libraries without using functions, or first getLoadLibraryandGetProcAddressand then continue as the first approach. With this approach, the analyst won’t find any imports which makes this technique stealthy but it needs the unpacking stub to be complex.
How to recognize the packed files?
There are many indications that the executable is packed, like:
-
The program has few imports, particularly if the only imports are
LoadLibraryandGetProcAddress -
When the program is opened in IDA Pro, only a small amount of code is recognized by the automatic analysis.
-
The program shows section names that indicate a particular packer (such as UPX0).
-
Some tools can detect the packers such as
DIEandPEid -
Files with
high entropymay be packed. -
In the packed file the difference between
Size of rawdata andVirtual sizeis very big, and usually, the virtual size is larger than the size of raw data.